Monitoreo de Kubernetes con Fritas en 8 pasos.
Ingesta de K8s logs en RealTime con ELK + Kafka

Objetivo
Realizar una POC de monitoreo de logs en k8s, levantando el stack ELK (Elasticsearch, Logstash, Kibana), así como también un cluster de Apache Kafka con 3 nodos, utilizando containers Docker, con el objetivo de tener las herramientas necesarias para realizar ingesta, almacenamiento y visualización de logs de un cluster de Kubernetes en RealTime.
Pre-requisitos
- Manejo de SO GNU/Linux
- Conocimiento básico de Containers Docker
- Conocimiento básico de Kubernetes
- Una máquina con GNU/Linux, Docker y k3s instalados
Arquitectura
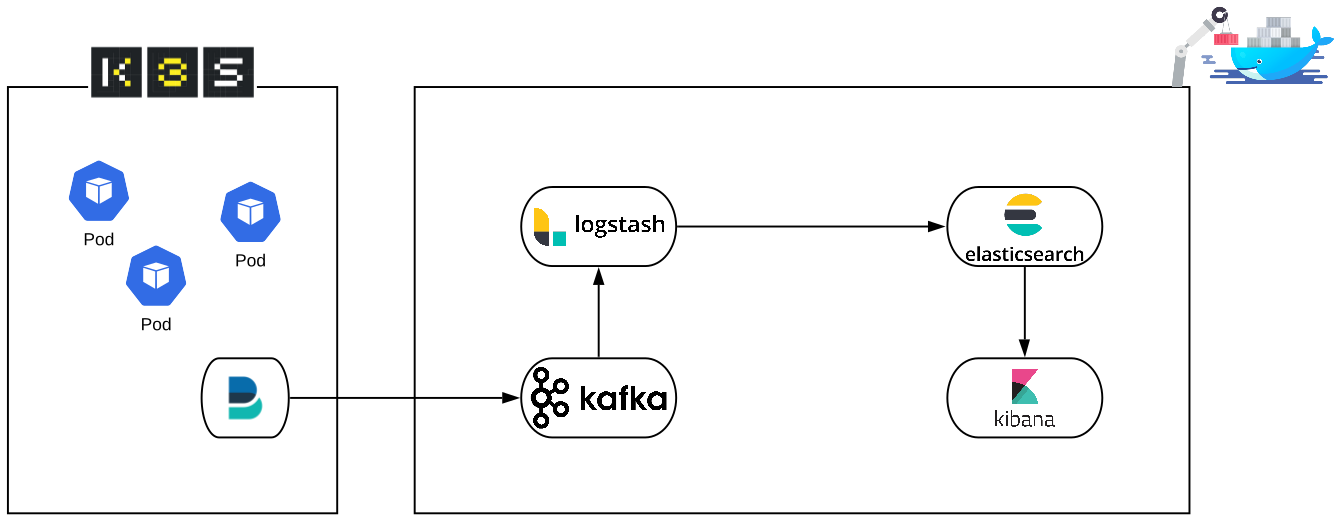
De izq a der, en esta POC vamos a tener nuestro cluster k8s soportado en la practica herramienta k3s de Rancher, dentro del cual vamos a deployar filebeat, básicamente lo que hace filebeat es capturar todos los logs del cluster y enviarlos a un destino en particular (output) que en este caso será el Kafka dockerizado. Luego tenemos nuestros containers Docker, Kafka para los que no lo conocen es un gestor de colas, en nuestro esquema, kafka va a recibir los logs que envía filebeat y los va a almacenar, nada más, así de sencillo. Logstash será el encargado de consumir los datos de Kafka, puede o no hacer algún tratamiento de esos datos, y se los envía a Elasticsearch para su almacenamiento en forma de índice y en formato JSON (Javascript Object Notation). Elasticsearch básicamente es un potente motor de base de datos orientado al almacenamiento y tratamiento de logs, en este punto, Elasticsearch va a almacenar nuestros logs y los disponibilizará mediante su API para cualquiera sea el consumidor de estos datos, en este caso Kibana. Con Kibana vamos a visualizar los datos almacenados en Elasticsearch, mapeando los índices de Elasticsearch con los index-patterns de Kibana. De esta manera vamos a tener un esquema de monitoreo de logs de kubernetes en tiempo real, con la posibilidad de realizar búsquedas, crear dashboards o triggerear alertas.
Levantemos todo en 8 sencillos pasos:
Paso 1: Pull de Imágenes ELK
Nos bajamos las últimas versiones de las imágenes Docker de ELK, al momento de escribir esta entrada es la 7.3.0
$ docker pull docker.elastic.co/elasticsearch/elasticsearch:7.3.0
$ docker pull docker.elastic.co/kibana/kibana:7.3.0
$ docker pull docker.elastic.co/logstash/logstash:7.3.0
Paso 2: Creamos la Docker Network
Para que todos los containers puedan hablar entre ellos vamos a crear y a trabajar sobre la misma docker network:
$ docker network create -d bridge elasticnet
Paso 3: Levantamos Elasticsearch
Levantamos nuestro Elasticsearch, de ahora en adelante ES, con el siguiente comando:
$ docker run -d --network elasticnet -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" --name es1 docker.elastic.co/elasticsearch/elasticsearch:7.3.0
Que hace todo eso?:Levanta un container basado en la imagen oficial de ES atachandolo a la red elasticnet que creamos anteriormente y exponiendo dos puertos, el 9200 que es el puerto http REST de ES y el 9300 que es puerto de tipo Bynary Transport de ES.
Para comprobar que el container levantó correctamente, pueden hacerlo de muchas formas, por ej:
Ejecutando:
$ docker ps
o con un:
$ curl -XGET http://localhost:9200
o también accediendo a http://localhost:9200 en el browser:
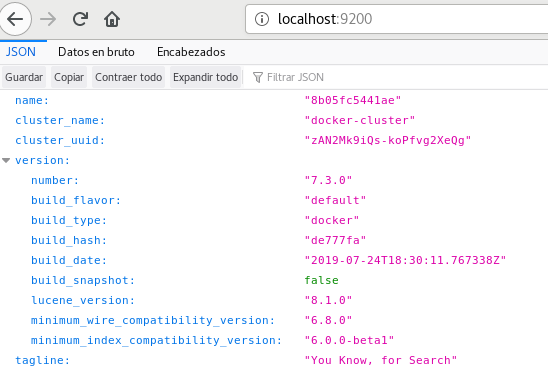
Esa es la API de ES contestando, podemos hacer absolutamente todo en ES a través de API calls, para más información del manejo de la API al final del post dejo algunos enlaces
Paso 4: Levantemos Kibana
Ejecutamos lo siguiente:
$ docker run -d --network elasticnet --link es1:elasticsearch -p 5601:5601 --name K1 docker.elastic.co/kibana/kibana:7.3.0
Que hace todo eso?:Levanta un container basado en la imagen oficial de Kibana atachandolo a la red elasticnet, exponiendo el puerto correspondiente, y finalmente especificando a Kibana donde se encuentra ES para poder conectarse con este último.
Comprobamos que levantó correctamente accediendo a http://localhost:5601 en el browser:
Paso 5: Levantemos Kafka
Zookeeper
Apache Kafka como habíamos mencionado es sencillamente una herramienta para manejo de colas, vamos a levantarlo en conjunto con Zookeeper, un proyecto también de Apache que nos va a ayudar a gestionar y coordinar el workload de nuestro cluster Kafka de 3 nodos:
Vamos a abrir 3 terminales diferentes y a ejecutar los siguientes comandos:
$ docker run -it --name zookeeper1 -e ZOO_MY_ID=1 -e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888" --network elasticnet --restart always --publish 2181:2181 zookeeper:3.4
$ docker run -it --name zookeeper2 -e ZOO_MY_ID=2 -e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888" --network elasticnet --restart always --publish 2182:2181 zookeeper:3.4
$ docker run -it --name zookeeper3 -e ZOO_MY_ID=3 -e ZOO_SERVERS="server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888" --network elasticnet --restart always --publish 2183:2181 zookeeper:3.4
Que hace todo eso?:Levanta 3 containers (o 3 nodos) de Zookeeper los cuales nos van a ayudar a coordinar el workload de Kafka, más adelante tendrán más sentido estos containers.
Kafka
Vamos a crear la siguiente estructura:
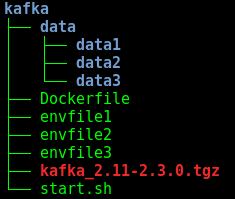
- Los directorios data van a estar vacíos por el momento.
-
Crear el Dockerfile con el siguiente contenido:
FROM java:8 MAINTAINER Juan Matias Kungfu de la Camara Beovide <juan.delacamara@3xmgroup.com> ENV KAFKA_RELEASE_ARCHIVE="kafka_2.11-2.3.0.tgz" RUN mkdir /kafka /data /logs # Copy Kafka binary distribution COPY ${KAFKA_RELEASE_ARCHIVE} /tmp WORKDIR /tmp # Install Kafka to /kafka RUN tar -zx -C /kafka --strip-components=1 -f ${KAFKA_RELEASE_ARCHIVE} && \ rm -rf ${KAFKA_RELEASE_ARCHIVE} COPY start.sh /kafka/start.sh # Set up a user to run Kafka RUN groupadd kafka && \ useradd -d /kafka -g kafka -s /bin/false kafka && \ chown -R kafka:kafka /kafka /data /logs && \ chmod ug+rx /kafka/start.sh USER kafka ENV PATH /kafka/bin:$PATH WORKDIR /kafka CMD ["./start.sh"] - Crear los envfiles con el siguiente contenido:
envfile1
BROKER_ID=1
BROKER_PORT=9091
BROKER_PORT_I=9094
BROKER_SERVER=
KAFKA_NODE_QTY=3
ZOOKEEPER_CONNECT=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
KAFKA_DATA_DIR=/data
KAFKA_TOPICS=
KAFKA_CREATE_TOPICS=0
KAFKA_NODE_NAME=kafka1
envfile2
BROKER_ID=2
BROKER_PORT=9092
BROKER_PORT_I=9095
BROKER_SERVER=
KAFKA_NODE_QTY=3
ZOOKEEPER_CONNECT=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
KAFKA_DATA_DIR=/data
KAFKA_TOPICS=
KAFKA_CREATE_TOPICS=0
KAFKA_NODE_NAME=kafka2
envfile3
BROKER_ID=3
BROKER_PORT=9093
BROKER_PORT_I=9096
BROKER_SERVER=
KAFKA_NODE_QTY=3
ZOOKEEPER_CONNECT=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
KAFKA_DATA_DIR=/data
KAFKA_TOPICS=
KAFKA_CREATE_TOPICS=0
KAFKA_NODE_NAME=kafka3
-
Descargar el binario de Kafka del siguiente enlace, ojo con la version que descargan y la que referencian en el Dockerfile, debe ser la misma para que no de errores el build.
-
Crear el script start.sh con el siguiente contenido:
#!/bin/bash echo "Replacing env values into server.properties" echo " BROKER_ID = $BROKER_ID" sed -i 's/broker.id=0/broker.id='"$BROKER_ID"'/g' config/server.properties echo " KAFKA_NODE_NAME:BROKER_PORT = $KAFKA_NODE_NAME:$BROKER_PORT" echo " BROKER_PORT_I = $BROKER_PORT_I" echo " " >> config/server.properties echo "advertised.listeners = OUTSIDE://$KAFKA_NODE_NAME:$BROKER_PORT,INSIDE://:$BROKER_PORT_I" >> config/server.properties echo "listeners = OUTSIDE://:$BROKER_PORT,INSIDE://:$BROKER_PORT_I" >> config/server.properties echo "listener.security.protocol.map = OUTSIDE:PLAINTEXT,INSIDE:PLAINTEXT" >> config/server.properties echo "inter.broker.listener.name = INSIDE" >> config/server.properties echo " log.dirs" sed -i 's/log.dirs=.*/log.dirs=\/data/g' config/server.properties echo " ZOOKEEPER_CONNECT = $ZOOKEEPER_CONNECT" sed -i 's/zookeeper.connect=localhost:2181/zookeeper.connect='"$ZOOKEEPER_CONNECT"'/g' config/server.properties echo "Starting server" ./bin/kafka-server-start.sh config/server.properties
Buildeamos Kafka:
$ docker build -t kafka-elk .
Levantamos los containers: Abrimos 3 terminales y ejecutamos los siguientes comandos, uno por terminal:
$ docker run -it --expose 9091 --expose 9094 -p 9091:9091 --env-file ./envfile1 -v /$(pwd)/data/data1:/data:Z --network=elasticnet --name kafka1 kafka-elk
$ docker run -it --expose 9092 --expose 9095 -p 9092:9092 --env-file ./envfile2 -v /$(pwd)/data/data2:/data:Z --network=elasticnet --name kafka2 kafka-elk
$ docker run -it --expose 9093 --expose 9096 -p 9093:9093 --env-file ./envfile3 -v /$(pwd)/data/data3:/data:Z --network=elasticnet --name kafka3 kafka-elk
Que hace todo eso?:Levanta 3 containers (o 3 nodos) de Kafka atachandolos a la red elasticnet, exponiendo los puertos correspondientes, especificando para cada nodo su envfile (en el cual vamos a referenciar a los containers Zookeeper también) y montando los directorios data que Kafka a utilizar para almacenar información de sus procesos.
En este punto ya tendremos levantado nuestro cluster Kafka con Zookeeper como coordinador y gestor de workloads, y tendremos 6 terminales corriendo en modo debug para ver el comportamiento de los nodos Kafka y Zookeeper en conjunto:
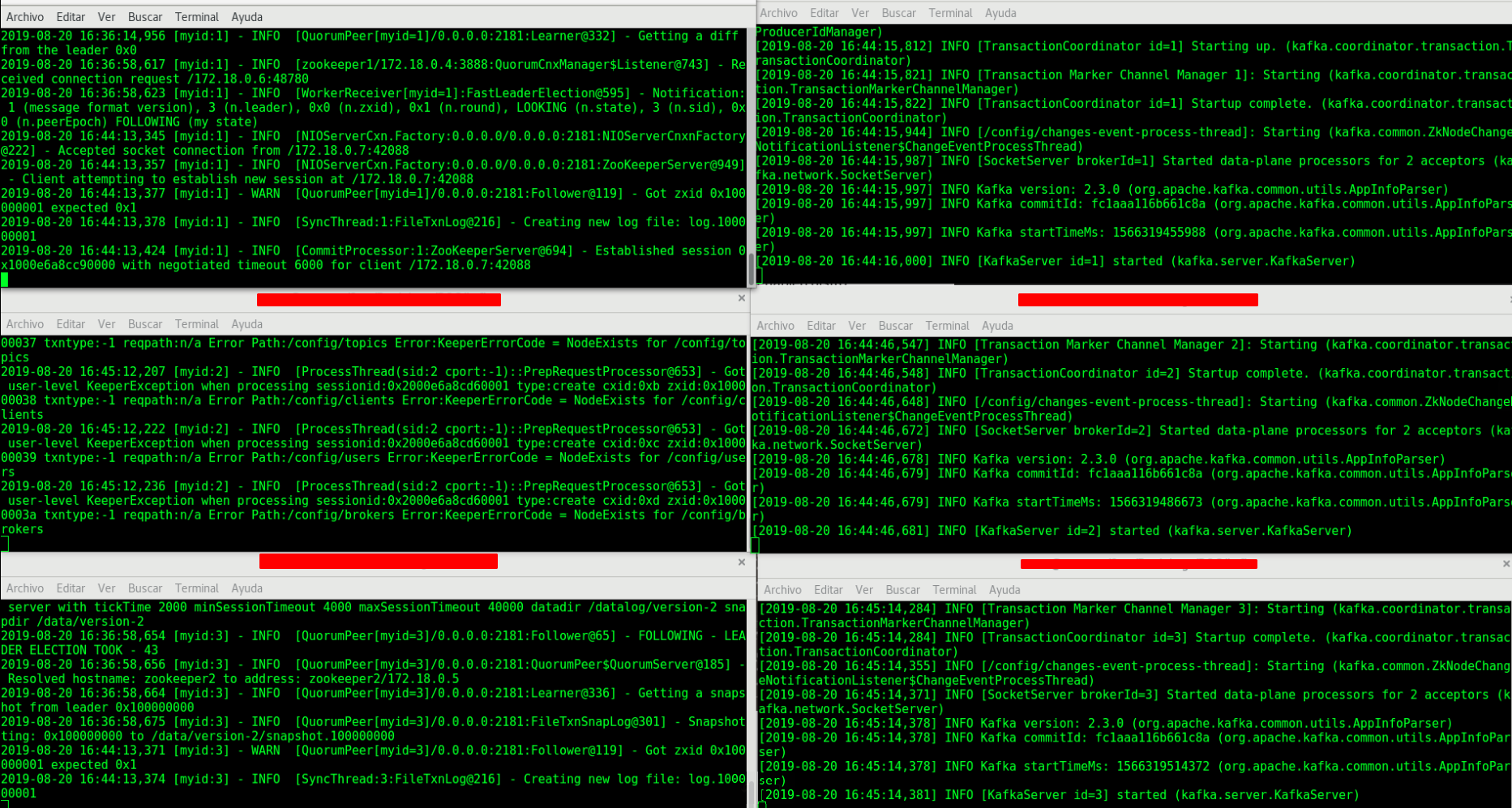
A la izquierda Zookeeper nodes, a la derecha Kafka nodes, si no desean ver el modo debug de estos containers, o no les gusta tener muchas terminales abiertas (jaja), recuerden levantarlos con el flag -d.
Paso 6: Levantemos Logstash
Crear la siguiente estructura:
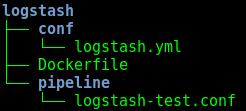
-
Contenido de logstash.yml:
http.host: "0.0.0.0" xpack.monitoring.enabled: "false" -
Contenido de logstash-test.conf:
input { kafka { bootstrap_servers => 'kafka1:9091' topics => ['filebeat'] } } filter { } output { elasticsearch { hosts => ['es1:9200'] manage_template => false index => 'index-filebeat-%{+YYYY.MM.dd}' } }
Con esta conf, estamos diciendole a Logstash: “hace un pull de toda la data que llegue a Kafka bajo el tópico filebeat, y reenviala a ES dando de alta un índice con el nombre index-filebeat-fechaDeHoy”.
-
Contenido del Dockerfile:
FROM docker.elastic.co/logstash/logstash:7.3.0 RUN rm -f /usr/share/logstash/pipeline/logstash.conf ADD pipeline/ /usr/share/logstash/pipeline/ ADD conf/ /usr/share/logstash/config/
Nos basamos en la imagen oficial descargada en paso 1, limpiamos la conf por si acaso, y finalmente agregamos la nuestra.
Buildeamos Logstash
$ docker build -t logstash-kafka .
Levantamos nuestro Logstash
$ docker run -ti -d --network elasticnet --name logstash logstash-kafka
Checkpoint:
En este punto, si no tuvimos ningún problema levantando los containers, deberíamos contar con 9 containers corriendo en nuestra network elasticnet:
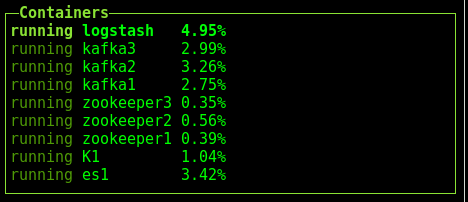
los cuales son: ES, Kibana, Logstash y los 6 containers involucrados en la gestión de colas Kafka.
Hasta acá, en teoría, si pusieramos datos en nuestro Kafka bajo el tópico filebeat, Logstash tomaría esos datos y se los re-enviaría a ES en forma de índice, y nosotros desde Kibana podríamos crear un IndexPattern y asociarlo dicho índice para visualizarlo.
podemos crear tópicos de manera manual en kafka, para una pequeña prueba, pero en lugar de eso vamos a levantar un cluster k8s en k3s, levantar un filebeat, probar la ingesta de logs de manera automática y ver como toda la info recorre nuestra arquitectura de monitoreo…… suena mucho más copado no??.
Paso 7: Levantemos Filebeat en K3s
Ya con nuestro cluster k8s corriendo en k3s, vamos a levantar Filebeat como DaemonSet, utilizando el yaml oficial que ofrece elastic:
$ curl -L -O https://raw.githubusercontent.com/elastic/beats/7.3/deploy/kubernetes/filebeat-kubernetes.yaml
Solamente deberíamos modificar el output en el ConfigMap para que apunte a nuestro kafka y para que escriba datos usando el tópico filebeat, y en el DaemonSet apuntar al puerto y host que corresponda a nuestro Kafka:
NOTA: El yaml viene por default para que filebeat viva en kube-system, lo cual nos viene muy bien para nuestra POC, ya que vamos a tener datos del resto de los objetos de kube-system, pero sientanse libre de hacer las modificaciones que crean necesarias para sus entornos, este post no contempla buenas prácticas k8s ni de seguridad, levantamos el filebeat por default para tener una fuente de datos más cercana a un entorno real.
Levantamos Filebeat con:
$ kubectl create -f filebeat-kubernetes.yaml
Verificamos:
$ kubectl get po -n kube-system

NOTA: tengan en cuenta que en esta POC, tenemos a k3s corriendo en nuestro Host, y el deployment de Filebeat debe escribir datos en nuestro Kafka, ergo, vamos a necesitar que nuestro cluster k8s se comunique con nuestros containers dentro de la docker network para escribir los logs en Kafka, para esto existe un proyecto opensource muy copado llamado dns-proxy-server muy facil de implementar, yo lo resolví de esa manera, pero también podrían referenciar la IP de los containers dentro del deployment de Filebeat y funcionaría, aunque esto último no es una práctica recomendada ya que no sería escalable, por lo tanto recomiendo que levanten su container dns-proxy-server para realizar este último paso.
Paso 8: Verificamos la Ingesta de Logs
En este punto, nuestro Filebeat estará capturando logs del cluster K8s y escribiendo esa data en Kafka usando el tópico filebeat, esto lo podemos verificar accediendo por ej al nodo kafka2 usando bash y ejecutando:
./bin/kafka-console-consumer.sh --bootstrap-server kafka1:9091 --from-beginning --topic filebeat
Pero NO es la idea verificarlo manualmente, en lugar de eso, vamos a asumir que hicimos todo el despliegue correctamente y que los datos de logs de k8s hicieron el recorrido completo, es decir, k3s -> filebeat -> kafka -> logstash -> ES -> Kibana, y vamos a ir a abrir en nuestro browser la siguiente dirección:
http://localhost:9200/_cat/indices?v
Esto nos devolverá todos los índices que posee ES:

Voila !!! ahí está nuestro índice generado por los logs de nuestro cluster k8s a través de filebeat-kafka-logstash-ES, ahora solo hay que mapearlo en Kibana para que toda esa info sea un poco más útil.
Abrimos Kibana y vamos a la sección Managment->Index patterns->Create index pattern y seleccionamos nuestro índice index-filebeat-fecha, listo, ahora si vamos al Discover de Kibana, vamos a ver como los logs de nuestro cluster k8s comienzan a llegar en tiempo real.
La ingesta de logs funciona correctamente, ya tenemos la info en Kibana para poder manipularla, hacer troubleshooting de nuestro cluster, crear dashboards o setear alarmas, luego, con logtash podemos ir parseando los campos que nos interesen para agregar más valor a nuestro monitoreo dependiendo del caso de uso.
8 pasos es mucho ?
Ya vimos el paso a paso de cada componente de nuestra arquitectura y entendimos que función cumple cada uno de ellos levantando cada container por separado y de manera manual. La evolución de esto podría ser meter todo dentro de un Docker Compose para desplegar todo en 1 paso ; o mejor aún armar directamente deployments K8s de nuestro ELK y Kafka, y añadiendo un poco mas de automatización armar todo el cluster con manifiestos Terraform, de esta manera tendremos nuestro esquema de monitoreo de logs en tiempo real disponible para trabajar con cualquiera sea el source de los logs simplemente pegandole al “servicio de monitoreo” en un determinado endpoint y con el plus de levantar todo el aproach con un simple apply de Terraform, un claro beneficio que nos brinda trabajar con IaC.
Basado en:
El deploy del stack Elasticsearch, Kibana y Kafka de esta POC está basado en los siguientes posts:
- Deploy de Elasticsearch y Kibana con Docker, uso de API de ES - Juan Matias DLCV
- Patterns y Field Mapping - Juan Matias DLCV
- Kafka - Juan Matias DLCV